Each year over the past decade, research output has grown steadily, according to the National Science Foundation. Researchers looking to parse vast amounts of available data are turning to text and data mining platforms, which use machine learning to analyze data sets for relationships and patterns. Many vendors are now offering software designed specifically for exploring their—as well as libraries’ own—collections. Here we talk with three library workers about their experiences with these platforms.
Gale Digital Scholar Lab

User: Hillary Richardson, coordinator of undergraduate research and information literacy at Mississippi University for Women in Columbus
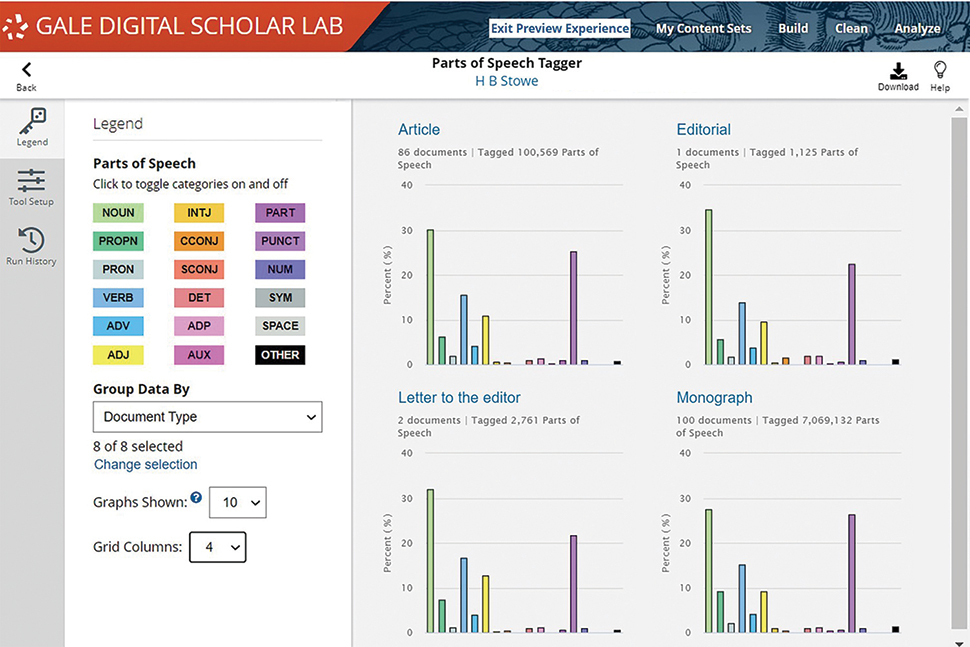
What is Gale Digital Scholar Lab? It’s a way for us to engage with some of Gale’s digital primary collections through text analysis tools.
How do you use Gale Digital Scholar Lab? I teach an introduction to digital research class and the digital studies practicum, and we use the Digital Scholar Lab to help us get across some of those competencies. We first used it to investigate some of the primary source collections that we have access to through Gale. We’ve also begun to upload some of our own collections, including the Smith Family Papers, which includes about 6,000 letters and diaries from 1908 to about 1977. Students are using text analysis tools like sentiment analysis, topic modeling, and n-gram analysis to see if they can discern patterns in the Smith letters.
What are the main benefits? If you wanted to do sentiment analysis without the sentiment analysis tool in Digital Scholar Lab, you’d have to know a little bit about Python, which has a steep learning curve. Having something like the Digital Scholar Lab helps lower the barrier to this type of analysis. My hope is that this tool will be a springboard for people to learn on their own and deepen their knowledge of things like topic modeling.
What would you like to see improved or added to the platform? The process of uploading something and adding it to a tool to be analyzed was a little bit clunky, but Gale has been troubleshooting that. I’d also like to be able to embed a dynamic text analysis visualization—not just an image file—into a digital exhibit.
Nexis Data Lab

User: Stephanie Labou, data science librarian at University of California San Diego in La Jolla
What is Nexis Data Lab? Nexis Data Lab is a platform that allows users to use text and data mining techniques on the content from LexisNexis. It lets users search for and select up to 100,000 documents, then analyze those documents in a Jupyter Notebook interface. Users can write their own Python code or adapt existing sample code provided in the interface.
How do you use Nexis Data Lab in your library? We are currently in the trial phase for Nexis Data Lab. We’ve received positive feedback from the test users so far for ease of use in accessing and analyzing content.
What are the main benefits? The primary benefit is really access—this is the only way to programmatically analyze a large number of documents from LexisNexis, which is something we get requests for a lot in our library. Plus, from my experience, analyses run extremely fast in the notebook environment—there are no delays or lags that sometimes occur with web-hosted analysis platforms.
What would you like to see improved or added to the platform? We’re looking forward to when LexisNexis’s legal and business content is available to analyze through Nexis Data Lab. The primary technical update I’d like to see eventually is the ability to make even larger corpora. The limit of 100,000 documents won’t be a problem for many researchers, but for those working on popular topics, especially over time, they may exceed this limit. Plus, having a variety of sample code is always useful—the more samples on popular text mining topics like sentiment analysis and topic modeling, the easier it is for users to get started.
ProQuest TDM Studio


Users: Ethan Pullman, first-year writing librarian, and Huajin Wang, senior librarian, at Carnegie Mellon University in Pittsburgh
What is ProQuest TDM Studio? TDM Studio is a data mining platform that allows you to use the text and data in the ProQuest database as well as your own while working in a coding environment with your team. It’s a way to visualize the relationship between texts and data more quickly than reading.
How do you use TDM Studio in your library? We use the platform for both digital humanities and science analysis. There’s a basic station that you can work from for data visualization that requires no coding, but through the coding workbench you’re also able to clean it up and control for things that aren’t necessarily in the default options. In our Data Collaborations Lab, we have researchers using TDM Studio as the first step in creating a knowledge base using existing publications for materials science. We’re doing benchmarking and literature reviews using this tool. There’s also a lot of work in our English department dealing with data mining and texts.
What are the main benefits? One big advantage is being able to access and analyze ProQuest’s text and data. TDM Studio allows you to directly use the data or put it into a work environment, and the workflow aspect is also good. The biggest value is the ability to identify and visualize the text to find things like relationship patterns, which is useful for people studying discourse and pattern recognition.
What would you like to see improved or added to the platform? We’d like to see TDM Studio include non-English and right-to-left languages. For those who work with non-English texts, it would be a great improvement. We would also really like to see a dashboard that provides information on how TDM Studio is being used.

